
今天,我们再次聚焦DeepSeek团队,他们的最新论文《Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures》无疑又在AI圈掀起了一阵波澜。署名作者包括梁文锋等多位核心成员,这似乎预示着DeepSeek-V3不仅仅是一次技术迭代,更是一次战略宣言。然而,在这份看似光鲜的报告背后,我们是否应该冷静下来,用批判性的眼光审视其真正的价值和潜在的问题?
自2023年以来,大语言模型(LLM)的狂潮席卷全球,GPT-4o、LLaMa-3、Claude-3.5 Sonnet等等,一个个名字如雷贯耳。模型参数如同军备竞赛般膨胀,然而,光鲜的性能背后,是日益凸显的硬件瓶颈。传统的“堆算力”模式,就像给一辆自行车装上火箭引擎,看似动力十足,实则难以驾驭。高昂的训练成本、惊人的能耗、以及扩展性的限制,让人们开始反思:这条路是否真的走得通?
DeepSeek团队提出的“硬件感知模型协同设计”理念,乍听之下颇具新意。但说白了,这更像是在现有硬件条件下的一种妥协。与其说是主动创新,不如说是被动适应。在算力、内存、带宽等资源捉襟见肘的情况下,试图通过软件层面的优化来弥补硬件的不足,这本身就带有一种无奈的色彩。DeepSeek-V3的诞生,或许正是这种无奈的产物。
DeepSeek-V3声称要在2048块NVIDIA H800 GPU上,以远低于传统方案的成本,实现媲美超大规模集群的训练与推理能力。这听起来非常诱人,但仔细分析其采用的技术手段,却发现更多的是一种“精打细算”的策略,而非颠覆式的创新。

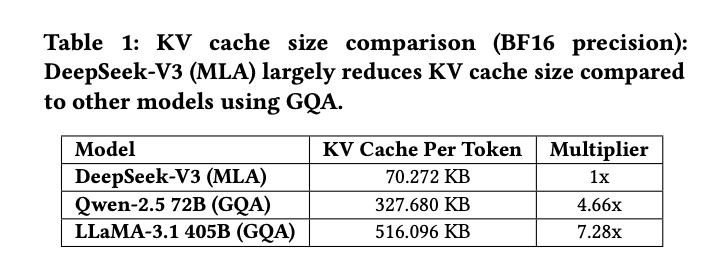
多头潜在注意力(MLA)和混合专家(MoE)架构,无疑是DeepSeek-V3的两大亮点。MLA通过压缩KV缓存,降低了显存占用,这在长文本推理和多轮对话场景下确实能缓解一定的压力。但这种压缩是否会牺牲模型的精度?潜在向量的表示能力是否足以捕捉所有重要的信息?这些问题都值得深入探讨。
MoE架构则通过“按需激活专家参数”,实现了模型参数量的指数级扩展。然而,这种稀疏性也带来了一些新的问题。例如,如何保证每个专家都能得到充分的训练?如何避免专家之间的负载不均衡?此外,MoE架构的通信开销也不容忽视。DeepSeek-V3声称其训练成本仅为同规模稠密模型的1/10,但这个数字是否考虑了所有相关的开销?
总而言之,DeepSeek-V3的架构创新,更像是在现有框架下的一种优化和改进。它并没有从根本上解决大模型训练的硬件瓶颈,而是在有限的资源下,尽可能地榨取更多的性能。这种“缝缝补补”的做法,或许能在短期内取得一定的效果,但长期来看,是否可持续?这仍然是一个未知数。
DeepSeek-V3为了解决大模型分布式训练中通信带宽和延迟的难题,提出了节点受限路由策略。这个策略的核心思想是将256个专家分为8组,每组部署在同一节点,从而确保每个token最多只需跨4个节点通信。乍一看,这似乎是一种巧妙的解决方案,能够充分利用NVLink节点内的高带宽,减少跨节点InfiniBand通信的压力,提升整体带宽利用率。
但是,这种策略也存在一定的局限性。首先,将专家固定在特定节点上,可能会导致负载不均衡。如果某些专家需要处理更多的请求,那么它们所在的节点可能会成为瓶颈。其次,节点受限路由策略牺牲了一定的灵活性。在理想情况下,模型应该能够根据实际的通信需求,动态地调整路由策略。但是,节点受限路由策略将路由限制在了固定的范围内,这可能会降低模型的整体性能。此外,这种策略对硬件的依赖性较高。如果硬件设备出现故障,那么整个路由策略可能会失效。
因此,节点受限路由策略更像是一种在特定硬件条件下进行优化的折衷方案,它在提升带宽利用率的同时,也牺牲了一定的灵活性和鲁棒性。它是否能够真正突破通信瓶颈,还有待进一步验证。
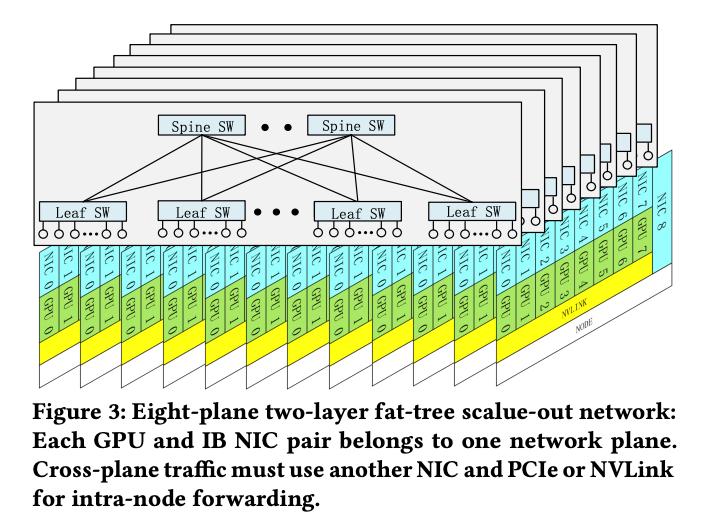
DeepSeek-V3还部署了多平面两层胖树(MPFT)网络拓扑,声称能够实现流量隔离和故障隔离,支持上万GPU的扩展,并且成本比传统三层网络降低40%,延迟减少30%。这听起来非常具有吸引力,但我们需要深入分析其背后的原理和潜在的风险。
MPFT网络的核心思想是将每个GPU-网卡对分配到独立的网络平面,从而实现流量隔离。这种做法可以有效地避免网络拥塞,提升整体吞吐量。但是,MPFT网络也增加了网络的复杂性。每个网络平面都需要独立的管理和维护,这会增加运维成本。此外,MPFT网络对硬件的要求也较高。每个GPU都需要配备多个网卡,这会增加硬件成本。
DeepSeek-V3声称MPFT网络在all-to-all通信和专家并行场景下,与单平面多轨网络性能几乎一致,但我们需要仔细研究其测试条件和数据。在实际应用中,MPFT网络的性能可能会受到多种因素的影响,例如网络拓扑结构、流量模式、以及硬件设备的性能等。此外,MPFT网络的扩展性也存在一定的限制。当GPU的数量超过一定阈值时,MPFT网络的性能可能会下降。
因此,MPFT网络更像是一种在成本和性能之间进行权衡的解决方案。它在降低成本的同时,也牺牲了一定的性能和扩展性。它是否能够真正突破网络瓶颈,还需要在实际应用中进行验证。
DeepSeek-V3宣称采用了双微批重叠(dual micro-batch overlap)技术,将MLA和MoE的计算与通信解耦为两个阶段,从而实现流水线并行,最大化GPU利用率。这种听起来很美好的技术,实际效果可能并没有想象中那么显著。
首先,流水线并行本身就存在一些固有的问题。例如,流水线的效率受到最慢阶段的限制,如果MLA或MoE的某个阶段耗时过长,那么整个流水线的效率都会受到影响。其次,双微批重叠需要精细的调度和同步,如果调度不当,反而会增加额外的开销。此外,这种技术对硬件的要求也较高,需要GPU能够支持高效的异步计算和通信。
在实际应用中,双微批重叠的效果可能会受到多种因素的影响,例如模型的大小、硬件的性能、以及任务的负载等。DeepSeek-V3声称这种技术能够最大化GPU利用率,但我们需要仔细研究其测试条件和数据。在某些情况下,双微批重叠的效果可能并不明显,甚至可能会降低模型的整体性能。
因此,双微批重叠更像是一种理论上的优化,其实际效果可能会受到多种因素的限制。它是否能够真正提升推理速度,还需要在实际应用中进行验证。
DeepSeek-V3引入了多token预测(MTP)模块,允许模型以较低成本并行预测多个候选token,并实时验证最优结果。DeepSeek团队宣称MTP可将生成速度提升1.8倍,准确率保持在80%-90%。这无疑是一个非常吸引人的特性,但我们有必要对其进行更深入的剖析。
MTP的核心在于并行预测多个token,这听起来似乎能够显著提升生成速度。然而,这种并行性是建立在一定的假设之上的,即模型能够以较低的成本预测多个候选token。在实际情况下,预测多个token的成本可能会很高,尤其是在模型规模较大、任务复杂度较高的情况下。
此外,MTP还需要实时验证最优结果,这需要额外的计算和通信开销。如果验证过程过于复杂,那么MTP的效率可能会大打折扣。DeepSeek-V3声称MTP能够将生成速度提升1.8倍,准确率保持在80%-90%,但我们需要仔细研究其测试条件和数据。在某些情况下,MTP的效果可能并不明显,甚至可能会降低模型的生成质量。
更重要的是,即使MTP能够提升生成速度,但它是否真的能够提升用户体验?如果用户更关注生成质量,那么MTP可能会适得其反。毕竟,速度的提升是以牺牲一定的准确率为代价的。
总而言之,MTP更像是一个吸引眼球的噱头,其实际效果可能并没有宣传的那么显著。它是否能够真正提升用户体验,还需要在实际应用中进行验证。
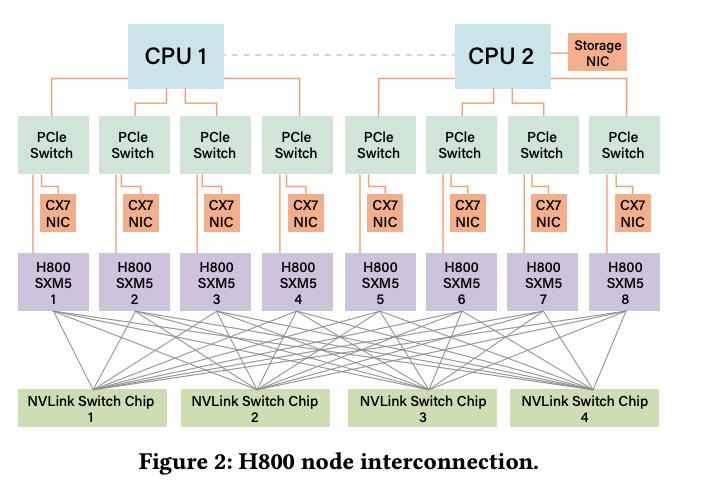
DeepSeek-V3 不仅采用了FP8,还大胆探索了LogFMT(对数浮点格式)等新型数据类型,这无疑是其在低精度计算领域的一次大胆尝试。在网络通信中,EP并行阶段使用FP8量化,通信量减少50%,这听起来确实很有诱惑力。DeepSeek团队甚至尝试将LogFMT集成到网络硬件,希望实现更高的信息熵密度和带宽利用率。然而,理想很丰满,现实却往往很骨感。
FP8虽然能够降低内存占用和计算量,但精度损失是不可避免的。DeepSeek-V3声称通过精细量化策略,将精度损失控制在0.25%以内,但这仍然是一个需要关注的问题。对于某些对精度要求极高的任务,FP8可能并不适用。此外,FP8的普及也面临着硬件和软件生态的挑战。目前,只有少数硬件设备支持FP8,并且相关的软件工具链还不够完善。
LogFMT则更像是一个充满未来感的概念。它在理论上具有更高的信息熵密度和带宽利用率,但目前受限于硬件算力和带宽,尚未大规模应用。DeepSeek团队也承认,LogFMT的集成仍然面临着巨大的挑战。即使未来硬件能够支持LogFMT,也需要重新设计底层的算法和数据结构,这无疑是一个漫长而艰巨的过程。
因此,DeepSeek-V3在低精度计算领域的探索,更像是一场豪赌。它赌的是未来硬件的发展趋势,赌的是软件生态的不断完善。如果DeepSeek团队赌对了,那么它将引领AI技术的新一轮革命。但如果赌错了,那么这些努力可能会付诸东流。毕竟,技术创新往往伴随着巨大的风险,而只有少数先行者能够最终获得成功。
DeepSeek团队在论文中提出了面向未来AI硬件架构的六大前瞻性建议,涵盖了稳定性、互连架构、智能网络、通信顺序、网络计算融合以及内存架构等多个方面。这些建议听起来非常美好,仿佛描绘了一个理想主义者的乌托邦。然而,仔细分析这些建议,我们不禁要问:它们真的具有可行性吗?
首先,关于稳定性优先的建议,强调了高级错误检测机制和全生命周期的数据完整性验证。这无疑是非常重要的,尤其是在大规模训练中,任何微小的错误都可能导致严重的后果。但是,实现这些高级错误检测机制需要付出巨大的代价,包括额外的硬件成本、更高的功耗、以及更复杂的软件管理。在追求性能的同时,我们是否能够兼顾稳定性?
其次,关于颠覆互连架构的建议,提议采用NVLink、Infinity Fabric等直连方案,或将CPU、GPU集成到同一扩展域。这无疑能够消除节点内瓶颈,提升系统吞吐量。但是,这些方案的实施也面临着巨大的技术挑战,需要突破现有的硬件和软件限制。此外,这些方案的成本也非常高昂,只有少数机构能够承担得起。
关于智能网络升级的建议,则更加充满未来感。集成硅光子学、基于信用的流控机制、自适应路由等等,这些技术都代表了未来网络的发展方向。但是,这些技术目前还处于研发阶段,距离实际应用还有很长的路要走。此外,实现智能网络需要复杂的算法和控制系统,这也会增加网络的复杂性和维护成本。
关于通信顺序硬件化、网络计算融合以及内存架构重构的建议,则更加具有前瞻性。这些建议都试图将计算和通信功能集成到硬件层面,从而提升系统的整体性能。但是,这些建议的实施难度非常大,需要对现有的硬件架构进行彻底的改革。此外,这些建议也面临着兼容性问题,如何保证新的硬件架构能够兼容现有的软件生态是一个巨大的挑战。
总而言之,DeepSeek团队提出的六大升级方向,更多的是一种对未来AI基础设施的愿景。这些建议虽然具有一定的参考价值,但在实际应用中面临着巨大的挑战。它们是否能够真正实现,还有待时间的检验。我们或许可以将这些建议看作是理想主义者的乌托邦,它们为我们指明了前进的方向,但同时也提醒我们,道路是漫长而艰辛的。
DeepSeek-V3的发布,被一些人解读为打破了超大规模集群的技术垄断,认为它证明了中小团队也能以有限资源实现顶级大模型训练与推理。这种观点过于乐观,甚至有些天真。
诚然,DeepSeek-V3在特定场景下展现出了一定的优势,例如在低成本训练和推理方面。但是,它并没有从根本上改变AI行业的格局。超大规模集群仍然是训练和部署大型AI模型的主流方式。DeepSeek-V3的出现,更像是在夹缝中求生存的一种策略,它试图在资源有限的条件下,尽可能地发挥自身的优势。
此外,DeepSeek-V3的技术门槛并不低。它需要精通软硬件协同设计、低精度计算、分布式系统等多个领域的知识。对于大多数中小团队来说,掌握这些技术仍然是一个巨大的挑战。因此,DeepSeek-V3的成功经验,很难被复制和推广。它或许能够启发一些人,但很难真正打破超大规模集群的技术垄断。
DeepSeek团队提出的软硬件协同理念,无疑是正确的。在AI领域,软件和硬件的协同优化是提升性能的关键。但是,这种理念在某种程度上也属于“正确的废话”。几乎所有AI从业者都明白软硬件协同的重要性,但真正能够将其付诸实践的却寥寥无几。
软硬件协同需要深入了解硬件的特性,并根据硬件的限制来设计软件。这需要软件工程师和硬件工程师之间的紧密合作,而这种合作往往面临着巨大的挑战。软件工程师可能不了解硬件的细节,而硬件工程师可能不了解软件的需求。此外,软硬件协同还需要大量的实验和调试,这需要付出巨大的时间和精力。
因此,软硬件协同虽然重要,但却很难真正实现。DeepSeek-V3在软硬件协同方面取得了一定的进展,但这并不意味着它已经解决了所有的问题。软硬件协同仍然是一个充满挑战的领域,需要更多的探索和实践。DeepSeek-V3的实践经验,或许能够为我们提供一些启示,但我们仍然需要脚踏实地,一步一个脚印地前进。
总而言之,DeepSeek-V3的发布,无疑是AI领域的一件大事。但是,我们应该保持冷静和客观,既要看到它的优点,也要看到它的局限性。它或许能够为我们提供一些新的思路和方法,但并不能解决所有的问题。在AI的道路上,我们仍然需要不断探索和创新。



RWA重塑DeFi:Ondo Finance鏈上國債創新,解鎖萬億市場
2025-05-22
比特幣崛起幕後推手:中本聰、Saylor領銜,蘇花公路般的爭議與創新
2025-05-22
